
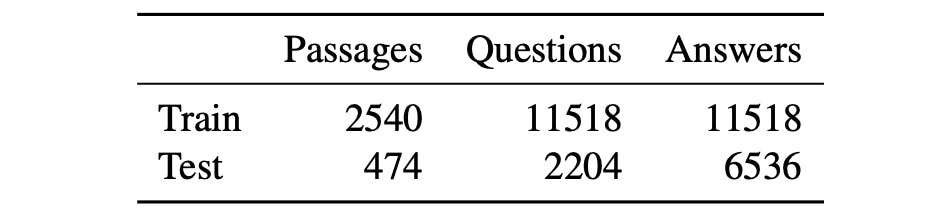
Squad Dataset German
Stanford Question Answering Dataset SQuAD is a reading comprehension dataset consisting of questions posed by crowdworkers on a set of Wikipedia articles where the answer to every question is a segment of text or span from the corresponding reading passage or the question might be unanswerable. From the German Wikipedia we extract each ar-.
Nlp Datasets Question Answering In German
Here is an example using the pipelines do to question answering.
Squad dataset german. This dataset can be explored in the Hugging Face model hub and can be alternatively downloaded with the Datasets library with load_datasetsquad_v2. In this example well look at the particular type of extractive QA that involves answering a question about a passage by highlighting the segment of the passage that answers the question. Download and import in the library the SQuAD python processing script from HuggingFace AWS bucket if its not already stored in the library.
Dataset load_dataset squad splitvalidation 10 This call to datasetsload_dataset does the following steps under the hood. All articles in this dataset are selected from Wikipedia. The General Language Understanding Evaluation GLUE benchmark is a collection of resources for training evaluating and analyzing natural language understanding systems.
What are future research areas. SQuAD Stanford Question Answering Dataset is a reading comprehension dataset consisting of questions posed by crowdworkers on a set of Wikipedia articles where the answer to every question is a segment of text or span from the corresponding reading. XQuAD Cross-lingual Question Answering Dataset is a benchmark dataset for evaluating cross-lingual question answering performance.
From these data points it seems fair to say that a dataset of around 25000 human annotated SQuAD style samples is enough to train a model with at least 90 of human performance. We will use the recipe Instructions to fine-tune our GPT-2 model and let us write recipes afterwards that we can cook. Hence I created a dataset consisting of historic match data for the German Bundesliga 1st and 2nd Division as well as the English Premier League reaching back as far as 1993 up to 2016.
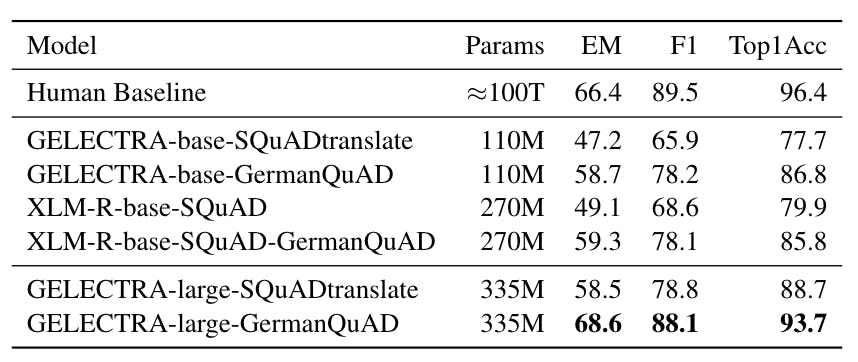
It leverages a fine-tuned model on. 21 Selection of Passages The basis of GermanQuAD is the German counter-part of English Wikipedia articles used in SQuAD. Announcing GermanQuAD and GermanDPR.
You can find the SQuAD processing script here for instance. Besides the mere information concerning goals scored and homedrawaway win the dataset also includes per site team data such as transfer value per team pre-season the squad strength etc. With 100000 question-answer pairs on 500 articles SQuAD is significantly larger than previous reading comprehension.
An example of a question answering dataset is the SQuAD dataset which is entirely based on that task. Extracting an answer from a text given a question. Spanish German Greek Russian Turkish Arabic.
And test datasets do not overlap like other popular datasets Lewis et al 2020b and include complex questions that cannot be answered with a single entity or only a few words. Of natural scenes in Chinese and English. The Norman dynasty had a major political cultural and military impact on medieval Europe and even the Near East.
I wrote 2 very important functions get_best_squad_n which given a squad formation and the players nationalities returns a squad with the best players in their respective positions according purely on the overall rating and get_summary_n which given a list of squad formation choices and the national team compares these different formations based on the average overall rating of the. If you would like to fine-tune a model on a SQuAD task you may leverage the run_squadpy. SQuAD is the Stanford Question Answering Dataset.
The French Italian Spanish Portuguese and Chinese models are monolingual language models trained on versions of the SQuAD dataset in their respective languages and their authors report decent results in their model cards eg. We are the creators of the German model and you can find out more about it here. Separately returns the traintest split.
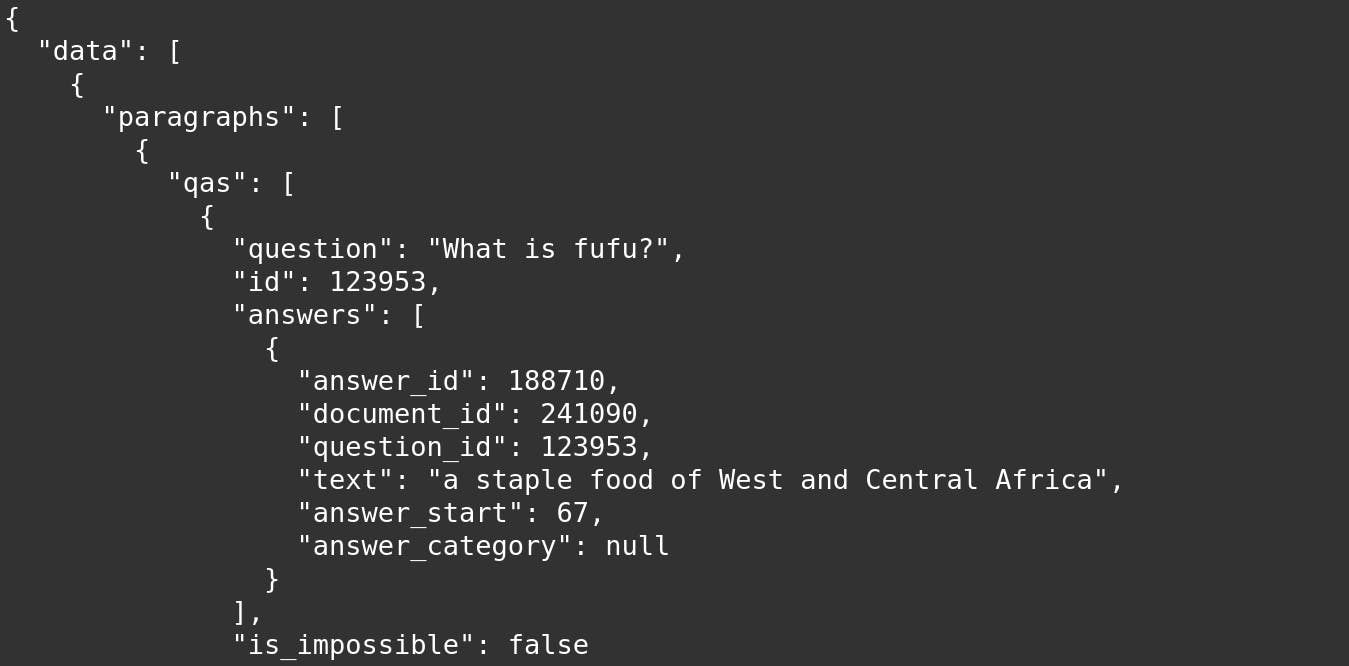
Fixes issue with small. An Exact Match score of 9006 on the SQuAD dataset. A SuperGLUE score of 889 which is a very significant improvement over the previous state-of-the-art result 846 and very close to human performance 898.
Great datasets like SQuAD and Natural Questions are the direct catalysts of the breakthroughs which deepset-ai Enabling German Neural Search. Here and hereThere also exist Korean QA models on the model hub but their. For example this multilingual BERT is trained on the Deepminds xQuAD dataset a multi-lingual version of the SQuAD dataset which supports 11 languages.
We can use a multi-lingual model pretrained on multiple languages. A benchmark of nine sentence- or sentence-pair language understanding tasks built on established existing datasets and selected to cover a diverse. Stanford Question Answering Dataset SQuAD is a new reading comprehension dataset consisting of questions posed by crowdworkers on a set of Wikipedia articles where the answer to every question is a segment of text or span from the corresponding reading passage.
In the tutorial we fine-tune a German GPT-2 from the Huggingface model hubAs data we use the German Recipes Dataset which consists of 12190 german recipes with metadata crawled from chefkochde. SogouNews torchtextdatasetsSogouNews rootdata splittrain test source. Question answering comes in many forms.
A ROUGE-2-F score of 2155 on the CNNDaily Mail abstractive summarization task. SQuAD is a reading comprehension dataset launched by Stanford University. Arabic German Greek English Spanish Hindi Russian Thai Turkish Vietnamese and Chinese.
SQuAD v11 consists of question-paragraph pairs where one of the sentences in the paragraph drawn from Wikipedia contains the answer to the corresponding question written by an annotator. The dataset consists of a subset of 240 paragraphs and 1190 question-answer pairs from the development set of SQuAD v11 Rajpurkar et al 2016 together with their professional translations into ten languages. The QNLI Question-answering NLI dataset is a Natural Language Inference dataset automatically derived from the Stanford Question Answering Dataset v11 SQuAD.
German Italian Portuguese and Russian as well as posters road signs packaging instructions menus etc.

Deepset Gelectra Large Germanquad Hugging Face
Nlp Datasets Question Answering In German
Nlp Datasets Question Answering In German

Nlp Datasets How Good Is Your Deep Learning Model

Xquad Dataset Papers With Code
Nlp Datasets Question Answering In German

Nlp Datasets Question Answering In German

Mrm8488 T5 Small Finetuned Squadv1 Hugging Face

Github Lttsh Cs224n Squad Cs224n Winter 2018 Project Squad
Github Ad Freiburg Large Qa Datasets A Collection Of Large Question Answering Datasets

Question Answering Papers With Code
Github Facebookresearch Mlqa New Dataset
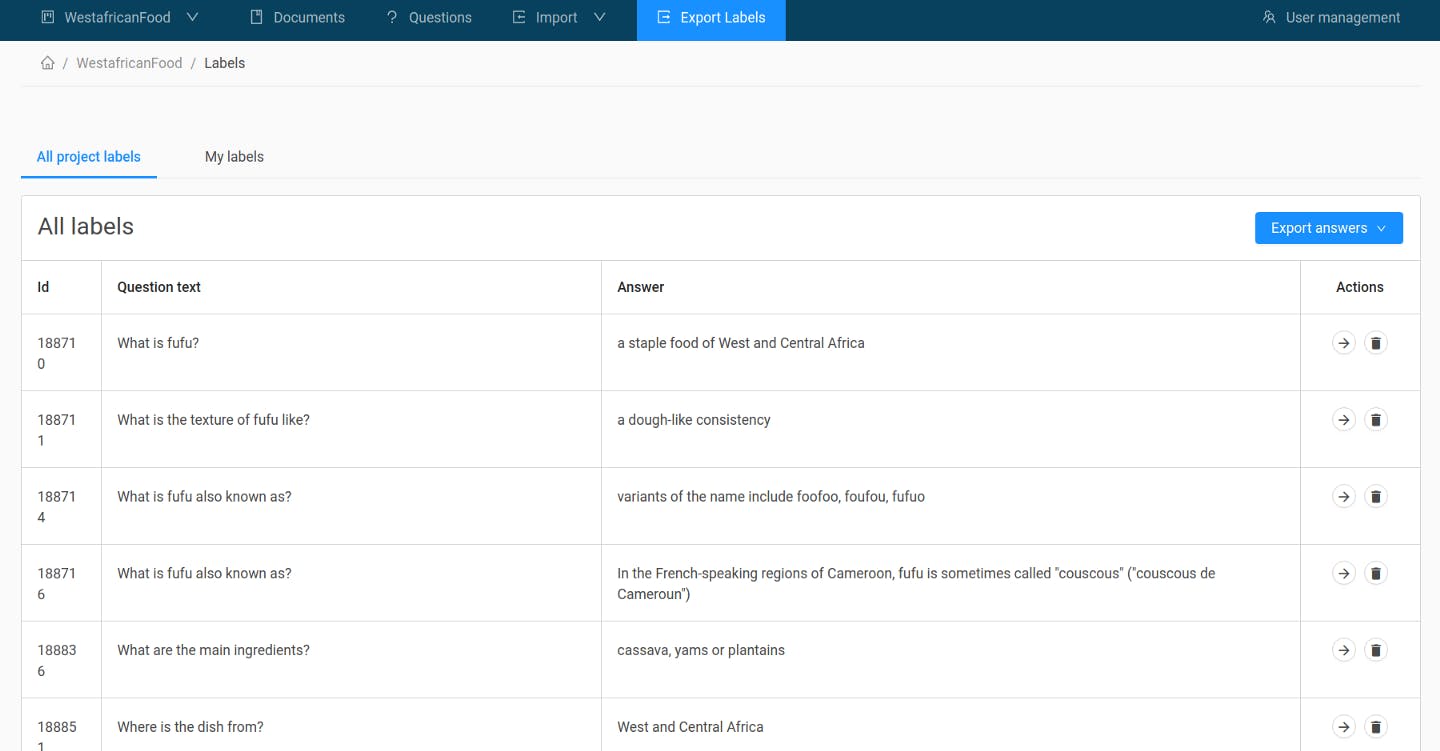
Germanbert For Question Answering Issue 475 Deepset Ai Farm Github

Text Corpus For Nlp
{kind=link}
Posting Komentar untuk "Squad Dataset German"